SIL Converters — Frequently asked Questions
Table of Contents for this page:
Frequently asked Questions
IPA data conversion
Frequently asked Questions
Question: How do I know whether I have 32 or 64-bit Microsoft Office?
- The easier way but does not always work
- In Word, File menu, Account, About Word
- After the title (About Microsoft® Word ) the next line starts with
- Microsoft® Word
- and ends with 32-bit or 64-bit.
- In Word, File menu, Account, About Word
- The harder way which should always work
- Press the Windows key, type
regeditto run Registry Editor, click Yes to allow changes (you don’t to actually make changes, but saying No means the tool will not run). - Search for
Bitnesswith the following options:- looking at Keys, Values and Data
- with Match whole string only.
- You should find one or more of the following keys (the number 16.0 might be different for your situation, depending on the version of Microsoft Office you have.
- Press the Windows key, type
HKLM\SOFTWARE\Microsoft\Office\16.0\Outlook
HKLM\SOFTWARE\Wow6432Node\Microsoft\Office\16.0\Outlook
HKLM\SOFTWARE\Microsoft\Office\ClickToRun\REGISTRY\MACHINE\Software\Microsoft\Office\16.0\Outlook
HKLM\SOFTWARE\Microsoft\Office\ClickToRun\REGISTRY\MACHINE\Software\Wow6432Node\Microsoft\Office\16.0\Outlook
Question: When I open a mapping file with the TECkit Unicode Mapping Editor I get an error message “unexpected character: “?” at line 1.” What can I do to get rid of this message?
Check whether you have another (different) version of the TECkit_x86.dll and/or TECkit_Compiler_x86.dll located somewhere in the path ahead of the version installed by SILConverters (i.e. C:\Program Files\Common Files\SIL). If so, this interferes with SILConverters finding the one it installed and the last time I encountered this, it was an older version of the TECkit DLL which prevents SILConverters clients from using the right version.
SILConverters v 4.0 has the latest versions of the TECkit DLLs and the location it is installed is also added to the path, so even if you deleted the (older?) ones in C:\Windows\System32 or lingualinks folder, the programs that installed them should continue to work (i.e. the interface has not changed, so they should still work fine).
Question: I am faced with a zillion files that need converting to Unicode. How do I prioritize my work?
You could divide your files into different types. Take into account the importance of the content related to your particular goals, the likelihood that the material would need to be re-used, etc.
This is how one person prioritized his work:
The documents of value, in order of priority would be:
- Scripture portions for abandoned projects.
- Published documents other than Scripture (which may need to be reprinted)
- Natural language texts: tales, stories, interviews.
- Dictionary data
- Unpublished documents such as primers, health guides, etc. Value
on these is low because it is unlikely that any new team will pick up
on them and complete them anyhow.
Do not bother converting ANY published or unpublished Scripture data unless it falls under #1 above. Scripture data is constantly changing and if it is more than a month old in an active project, it is already outdated. Find out where the most recent copy of the data is, and if it is safe and in standard format, that is worth more than 20 Word or Publisher files.
Question: I am using SIL Converters and would like to know how I can manually add a TECkit converter that does not have an installer.
These steps are for those who have an existing TECkit converter. They should also work, with reasonable modifications, for other types of converters supported by SIL Converters.
- Download and unzip your TECkit converter (some mapping files are found on this GitHub repo)
- Either run the “Data Conversion” macro
- (Tools / Data Conversion or in Word 2007+ Add-Ins / Data Conversion)
- Click the Select button to add your converter.
- Click Add New
- Or run the Clipboard EncConverter (which then doesn’t require having/starting Word and the complications of loading the document template)
- Start / All Programs / SIL Converters / Clipboard EncConverter
- When it shows up in the system tray, right-click on its icon and choose Add Converter.
- Select “TECkit map” and click on Add.
- Select the Setup tab.
- Select the … button and browse to the folder where you put your TECkit converter.
- Select your converter and click Open.
- Select Save in System Repository.
- Where it says to “Enter Converter Name” type in a name that will help you remember what the converter will do. Usually people choose a name that expresses both sides of the equation, for instance
SILIPA93Unicode. - Click Advanced and ensure that appropriate radio buttons are selected. Usually the default is OK.
- Click OK, OK. OK and OK.
Question: I know that when converting legacy text to Unicode (with TECkit) I can request either decomposed (NFD) or composed (NFC) result. But if the text is already Unicode, how do I convert it to NFD or NFC?
For text documents, you can do this with txtconv.exe (from the TECkit package); just run it with no mapping file, specifying a Unicode encoding form for both input and output, and give it the normalization option you want.
OR
With EncConverters installed (including the ICU Plug-in), you could do the following steps in Word:
- Run the “Data Conversion” macro
- Click the Select button to add a converter.
- Click Add New.
- Select “ICU transliterator” and click on Add.
- Select the Setup tab.
- At the “Built-in transliterator” radio button, select Any to NFD.
- Select Save in System Repository.
- Where it says to “Enter Converter Name” type:
Any to NFD. - Click Advanced and ensure that “ICU Transliteration” is selected.
- Click OK, OK. OK and OK.
- Repeat these steps to add a “NFC” converter.
Then you can use the main dialog interface to convert your word document according to your need using either of these two converters.
You can also write Word macros (after following the above steps) to do the conversion, but it depends on the version of the EncConverters you are using (the 1.5 version uses a slightly different interface than the 2.0 version). The 1.5 version should work, but the actual syntax of the VB code will be different from the following. In the Visual Basic editor, you have to do Tools / References, and check the box that looks like “EncCnvtrs” or “EncConverters”, then add the macros like the following:
; Add a reference to the SILConverters type lib (i.e. in the VBA editor (Alt+F11),
; click 'Tools', 'References' and then browse for file
; "C:Program FilesCommon FilesSILSilEncConverters22.tlb")
Sub Decompose()
Selection.Text = GetEncConverter("NFD").Convert(Selection.Text)
End Sub
Sub Compose()
Selection.Text = GetEncConverter("NFC").Convert(Selection.Text)
End Sub
Where the "GetEncConverter" function is defined as follows:
Function GetEncConverters() As EncConverters
Set GetEncConverters = CreateObject("SilEncConverters22.EncConverters")
End Function
Function GetEncConverter(sName As String) As IEncConverter
Set GetEncConverter = GetEncConverters().Item(sName)
End Function
Question: Is there any advantage in generating the BOM?
The Byte Order Mark (BOM) (U+FEFF) was invented back in the days when Unicode was thought of as a 16-bit standard. The problem was that some systems wanted to store Unicode little endian with the least significant byte first, and some wanted to store it big endian with the most significant byte in a pair coming first. In order to resolve this, the UTC allocated two codes: U+FEFF as a zero-width non-breaking space (which basically has no effect at the start of the file), and U+FFFE (the byte reversal of U+FEFF) as an unassigned and therefore illegal code. Therefore, to determine the byte order of a stream of data, a processor can examine the inital BOM: if it encounters U+FFFE, this indicates that the order of the bytes needs to be reversed (which will produce the valid code U+FEFF); if it finds U+FEFF then no change is needed.
With the advent of the various Unicode Transfer Formats (UTFs), the BOM concept was extended to UTF-32. UTF-8, on the other hand, does not strictly need an initial BOM because there are no byte order issues to deal with. But U+FEFF as encoded in the various UTFs does end up being a sequence that is very unlikely to occur in almost any other encoding. As such, U+FEFF can be used not only as a byte-order mark but also to indicate that the data in question is in fact Unicode text. Microsoft, for example, uses this extensively in its data.
There is a problem with using the BOM when storing data in UTF-8. Many programs that were not designed to be Unicode-aware work very well with UTF-8 encoded data. All codepoints up to x7F take their standard ASCII meanings, and all codes above x80 are considered just to be odd characters with no real interpretation required. Thus processors of certain kinds of ASCII text, such as programming source code, configuration files, etc., which assume that any significant characters will be in the range 0x00-0x7F, can work fine with UTF-8, since all characters in the higher range are just treated as unprocessed data that are handled by some other process. But if a file starts with a BOM (U+FEFF = xEF xBB xBF in UTF-8), those codes are all ‘upper ASCII’, not ASCII spaces that can be ignored. This can lead to various types of failure (errors, warnings, crashes). Increasingly, as such applications are updated, they are designed to ignore any initial BOM, but care should be taken and users should be aware that an initial BOM may cause problems in certain situations. Unfortunately, the chief culprits in creating such BOMs in the first place are the least able to remove it.
Another problem arises when files are blindly concatenated. U+FEFF is actually a ZERO WIDTH NO-BREAK SPACE and as such has specific semantics when it occurs in the middle of a file. But if a file with a BOM is simply concatenated to another file, then what was a BOM may suddenly occur in the middle of a file and have a change in semantics. For this reason, the UTC created the U+2060 WORD JOINER character to take over the nobreak space semantics of U+FEFF. But it is only safe to strip U+FEFF from within a text if one is sure that the data is conforming to Unicode 5.0 or later. (This means that the ZERO WIDTH NO-BREAK SPACE is now very poorly named, and unfortunately will remain so, since Unicode character names can never be changed.)
So what to do? Should one always insert a BOM even in UTF-8 text so that applications can identify the encoding? Or should one always remove them because they might cause problems? In the case of UTF-16 and UTF-32 data, the answer is obvious: a BOM is essential to give byte ordering information. But in the case of UTF-8 data the situation is more ambiguous.
BOMs should be inserted if they are needed and removed if they cause problems. Applications should be written to ignore BOM everywhere (if they are Unicode-aware) and especially file-initially (even if the application is not Unicode-aware). Files may or may not include a BOM and no strong efforts should be made either way, unless that data is being used in an application that requires either the presence or absence of a BOM. In other words, it does not matter what you do unless it matters, in which case do the right thing! As applications have become BOM insensitive it matters less and less whether UTF-8 data has a BOM or not.
Question: When I try to convert my file using the SIL Converters package some of the characters are not being converted. If I select the text that was not converted correctly and run the Unicode Word Macro “Show Unicode” I see that Word thinks every one of these is U+0028 ( LEFT PARENTHESIS. What is happening?
Use the Bulk Word document converter. It does convert Insert / Symbol occurrences. See below for instructions.
Question: I noticed in conversion that the IPA in the footnotes did not convert. And when I tried to do the conversion piece-by-piece funnier things happened. I selected one SILIPA93 character in a footnote, tried the Data Conversion macro, and the font fields came up blank. Any ideas what else I can do?
Use the Bulk Word document converter. See below for instructions.
Question: How do I use the Bulk Word Document Converter?
- Make sure Microsoft Word is closed
- Go to Start / All Programs / SIL Converters / Bulk Word Document Converter
- Click on File / Open and navigate to where your Word documents are.
- You may select one file or quite a few files.
- A dialog box will appear that shows you all the fonts used in those documents
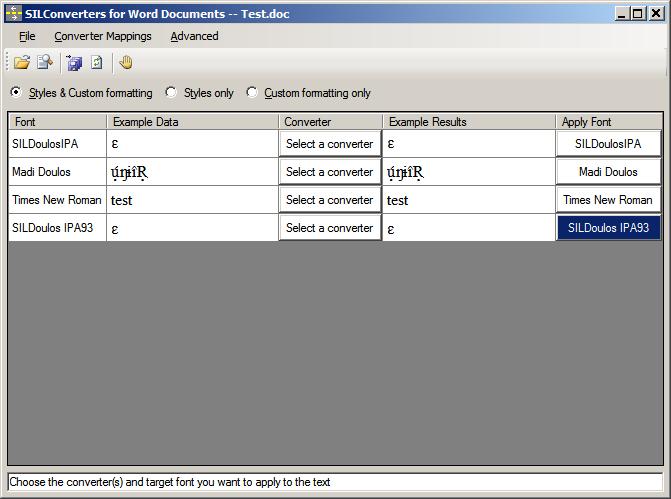
- For each custom-encoded font you should choose an appropriate converter (click on “Select a converter” and choose the converter)
- If you wish to use the same converter for the next font selection, you can just RIGHT-click your mouse button on “Select a converter” and it will automatically apply the last converter you selected. Otherwise, follow the same procedure as above to choose a different converter.
- For other fonts (like Times New Roman), you should not need to choose a converter
- For each custom-encoded font you should choose a Unicode font for “Apply font” (click on Apply Font and choose an appropriate font)
- If you wish to use the same font for the next font selection, you can just RIGHT-click your mouse button on “Select a font to apply” and it will automatically apply the last font you selected. Otherwise, follow the same procedure as above to choose a different font.
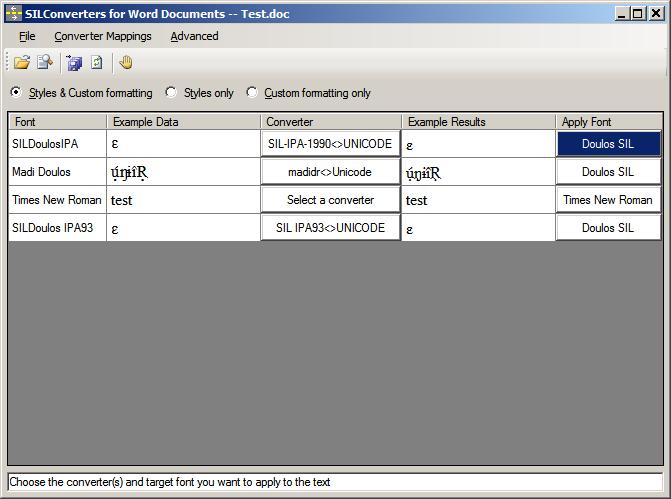
- Notice the “Example Data” window and the “Example Results” window. If the correct converter and correct font is applied, the results should look almost identical (at least they should be the same characters, if you chose a very different font, it could look different)
- Then click on the little floppy disks to convert the files and save
- You can choose to rename the converted files, or you could keep the same name if you put them in a different directory. It is probably better to give them a different name until you’ve confirmed the conversion was done properly.
- You may wish to save your settings file. This will save your information tieing custom-encoded fonts with an appropriate TECkit mapping and the Unicode font you wish to use. This will allow you to reuse these settings for another project.
- Select Converter Mappings and click on Save and Save.
Question: How do I use SILConverters to convert a Microsoft Publisher document to Unicode?
Hopefully you installed “SILConverters for Office” when you installed SIL Converters.
- Open your document in Publisher
- You will see a new toolbar that looks like this:

- If you want to convert your whole document you should click on Convert Whole Document. Otherwise choose Convert Selected Story or Convert Selection.
- Once you have clicked on one of the buttons, you will see a dialog box called “Choose fonts to convert”. This will list all the fonts in your document.
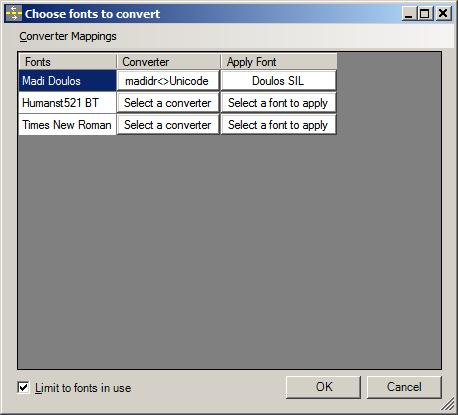
- For the first font you wish to run the converter on, click on “Select a converter”. If you’ve already installed your converter, you can just click on your converter.
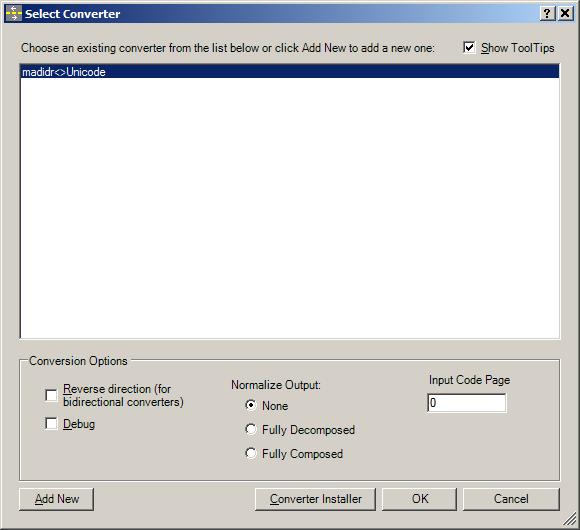
- Then click on OK.
- Next, click on “Select a font to apply” and choose the font you wish to use.
- If you wish to use the same converter for the next font selection, you can just RIGHT-click your mouse button on “Select a converter” and it will automatically apply the last converter you selected. Otherwise, follow the same procedure as above to choose a different converter.
- If you wish to use the same font for the next font selection, you can just RIGHT-click your mouse button on “Select a font to apply” and it will automatically apply the last font you selected. Otherwise, follow the same procedure as above to choose a different font.
- SIL Converters will take you to a dialog box which will show you how it will convert the first text. If it looks okay, you can choose Replace All and continue to choose that until you are finished converting your document.
- You will find that different fonts have a different amount of linespacing and your “stories” may not always fit in the same box you had them in. You can either adjust the linespacing for your story or adjust the size of the box.
IPA data conversion
Question: I have MS Word documents which use your SIL IPA93 custom-encoded fonts, but I want to begin using Unicode. Can you tell me how to convert my data to Unicode?
As you have implied, documents which were created (encoded) with legacy (custom-encoded) fonts are not compatible with Unicode fonts. You not only need to use a Unicode font, you will need to convert your data to Unicode.
Since you have MS Word documents it might be a straightforward solution. These instructions should work if you have MS Word 2003:
- Download and install Doulos SIL or Charis SIL.
- Download and install SIL Converters (follow the installation instructions on that page).
- When you get to the SIL Converters Install Options dialog box:
- Under Conversion Maps and Tables:
- Make sure SIL IPA93<>UNICODE is selected. If you plan to convert SIL-IPA-1990 data to Unicode you should also make sure SIL-IPA-1990<>UNICODE is selected.
- Click Apply
- Continue on with the installation.
- Under Conversion Maps and Tables:
- When you get to the SIL Converters Install Options dialog box:
- If multiple users on the machine want to use the document template (found in: (
C:\Documents and Settings\Application Data\Microsoft\Templates), you need to manually move the .DOT files to some common location and each user will need to browse for them individually in Tools / Templates and Add-Ins. If you want one or more of these document templates to start up automatically when Word starts, move them either to the current user’s Startup folder (i.e.C:\Documents and Settings\Application Data\Microsoft\Word\STARTUP). For all users, put it in the global startup folder (e.g.C:\Program Files\Microsoft Office\OFFICE11\STARTUP). - Open your document in MS Word.
- If you did not load the template in the manner specified above, you should follow these steps to activate the Conversion Macro Template:
- Click Tools / Templates and Add-ins…
- Click the Add button to browse for the Data Conversion Macro dot file (in,
C:\Documents and Settings\yourloginname\Application Data\Microsoft\Templatesby default). - Click OK to return to Word.
- Go to Tools / Data Conversion or in Word 2007+ Add-Ins / Data Conversion
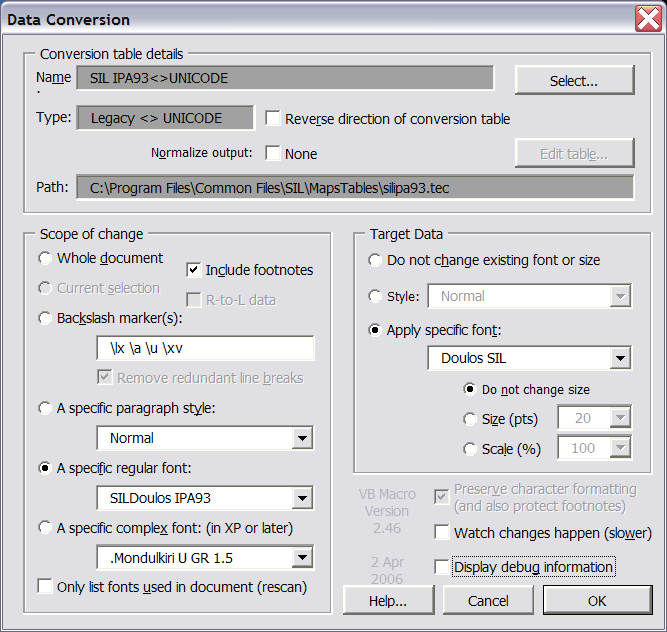
- Under Conversion table details, click on Select….
- Under Select Converter, select SIL IPA93<>UNICODE.
- Select OK.
- If you have footnotes, choose Include footnotes.
- Under Scope of change, select A specific regular font:.
- In the pull-down menu choose SILDoulos IPA93.
- Under Target Data choose Apply specific font:.
- In the pull-down menu choose Doulos SIL (or another appropriate Unicode font).
- Select OK.
- Be patient. With some documents the conversion process can take awhile. Do not assume that Word, or your computer, has hung.
- Follow these same instructions for converting your IPA-1990 (SILDoulosIPA font) data. However, instead of selecting the SIL IPA93<>UNICODE converter, you should select the SIL-IPA-1990<>UNICODE converter.
We hope your data will have converted correctly! These instructions are for converting your data in one document. Once you have tried it for one document and understand the concepts, you might want to use the Bulk Word Document Converter. (Start / Programs / SIL Converters / Bulk Word Document Converter) to do all your documents in one go. At this point we do not have step-by-step instructions, but basically you select your documents, choose your fonts, converter and font to apply.
Disclaimer:
Converting data to Unicode is not always straightforward and we do not have all the answers.
Question: I have plain text files which use your SIL IPA93 fonts, but I want to begin using Unicode. Can you tell me how to convert my data to Unicode?
- If you have not already installed SIL Converters, follow the instructions above.
- Click on Start / Programs / SIL Converters / TECkit / DropTEC.
- In Windows Explorer, navigate to
C:\Documents and Settings\All Users\Application Data\SIL\SILConverters40\MapsTables(or possiblyC:\ProgramData\SIL\SILConverters40\MapsTablesorC:\ProgramData\SIL\MapsTables). - From Windows Explorer, drag the compiled mapping file
silipa93.tecto the box at the top labeled “Mapping file:”. (Alternatively, you can use the adjacent Browse button and navigate to the file.) - From Explorer, drag your text file to the box on the left labeled “Legacy text file:” (alternatively, you can use the adjacent Browse button and navigate to the file). When you have loaded the file, DropTEC prompts you for a destination file. Click Save and accept the default name.
- Once you supply the name, the file is created, so if you want to select a different “Unicode output form”, you’ll need to do it before specifying the input file (and giving the name for the output file).
- Click on File / Exit of the “DropTEC” window to close the program.
- You should have a new Unicode-encoded text file.
Question: I have Standard Format Marker (sfm) text files and want to convert only one or two of the sf markers from an SIL IPA93 encoding to Unicode. Can I do that?
The Bulk SFM Converter will easily handle doing this.
- If you have not already installed SIL Converters, follow the instructions above.
- Click on Start / Programs / SIL Converters / Bulk SFM Converter.
- Click on File / Open SFM Documents / Non-Unicode (Legacy).
- Select your files and click on Open.
- For each SFM which uses the IPA93 fonts, click on Click here to define a converter.
- Select SIL IPA93<>UNICODE (note that you may select a different converter for each SFM — if needed).
- Click on OK.
- If you wish to preview whether the converter will work or not, you may select appropriate fonts
- For each SFM which uses the IPA93 fonts
- Right-click on Example Data and choose SILDoulos IPA93.
- Right-click on Example Results and choose Doulos SIL (or another appropriate Unicode font).
- For each SFM which uses the IPA93 fonts
- If the example results look right, move on to the next step.
- Click on File / Convert and Save SFM Documents / Unicode (UTF-8).
- Verify that the file name and location are appropriate and click on Save.